Time Series Forecasting
In this tutorial, we will demonstrate how to build a model for time series forecasting in NumPyro. Specifically, we will replicate the Seasonal, Global Trend (SGT) model from the Rlgt: Bayesian Exponential Smoothing Models with Trend Modifications package. The time series data that we will use for this tutorial is the lynx dataset, which contains annual numbers of lynx trappings from 1821 to 1934 in Canada.
[ ]:
!pip install -q numpyro@git+https://github.com/pyro-ppl/numpyro
[1]:
import os
from IPython.display import set_matplotlib_formats
import matplotlib.pyplot as plt
import pandas as pd
from jax import random
import jax.numpy as jnp
import numpyro
from numpyro.contrib.control_flow import scan
from numpyro.diagnostics import autocorrelation, hpdi
import numpyro.distributions as dist
from numpyro.infer import MCMC, NUTS, Predictive
if "NUMPYRO_SPHINXBUILD" in os.environ:
set_matplotlib_formats("svg")
numpyro.set_host_device_count(4)
assert numpyro.__version__.startswith("0.21.0")
Data
First, let’s import and take a look at the dataset.
[2]:
URL = "https://raw.githubusercontent.com/vincentarelbundock/Rdatasets/master/csv/datasets/lynx.csv"
lynx = pd.read_csv(URL, index_col=0)
data = lynx["value"].values
print("Length of time series:", data.shape[0])
plt.figure(figsize=(8, 4))
plt.plot(lynx["time"], data)
plt.show()
Length of time series: 114
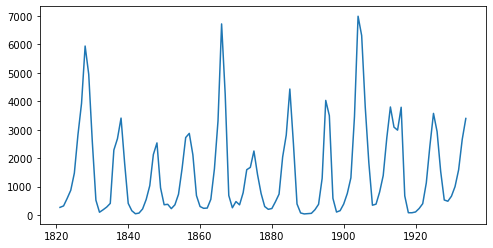
The time series has a length of 114 (a data point for each year), and by looking at the plot, we can observe seasonality in this dataset, which is the recurrence of similar patterns at specific time periods. e.g. in this dataset, we observe a cyclical pattern every 10 years, but there is also a less obvious but clear spike in the number of trappings every 40 years. Let us see if we can model this effect in NumPyro.
In this tutorial, we will use the first 80 values for training and the last 34 values for testing.
[3]:
y_train, y_test = jnp.array(data[:80], dtype=jnp.float32), data[80:]
Model
The model we are going to use is called Seasonal, Global Trend, which when tested on 3003 time series of the M-3 competition, has been known to outperform other models originally participating in the competition:
\begin{align} \text{exp-val}_{t} &= \text{level}_{t-1} + \text{coef-trend} \times \text{level}_{t-1}^{\text{pow-trend}} + \text{s}_t \times \text{level}_{t-1}^{\text{pow-season}}, \\ \sigma_{t} &= \sigma \times \text{exp-val}_{t}^{\text{powx}} + \text{offset}, \\ y_{t} &\sim \text{StudentT}(\nu, \text{exp-val}_{t}, \sigma_{t}) \end{align}
, where level and s follows the following recursion rules:
\begin{align} \text{level-p} &= \begin{cases} y_t - \text{s}_t \times \text{level}_{t-1}^{\text{pow-season}} & \text{if } t \le \text{seasonality}, \\ \text{Average} \left[y(t - \text{seasonality} + 1), \ldots, y(t)\right] & \text{otherwise}, \end{cases} \\ \text{level}_{t} &= \text{level-sm} \times \text{level-p} + (1 - \text{level-sm}) \times \text{level}_{t-1}, \\ \text{s}_{t + \text{seasonality}} &= \text{s-sm} \times \frac{y_{t} - \text{level}_{t}}{\text{level}_{t-1}^{\text{pow-trend}}} + (1 - \text{s-sm}) \times \text{s}_{t}. \end{align}
A more detailed explanation for SGT model can be found in this vignette from the authors of the Rlgt package. Here we summarize the core ideas of this model:
Student’s t-distribution, which has heavier tails than normal distribution, is used for the likelihood.
The expected value
exp_valconsists of a trending component and a seasonal component:The trend is governed by the map \(x \mapsto x + ax^b\), where \(x\) is
level, \(a\) iscoef_trend, and \(b\) ispow_trend. Note that when \(b \sim 0\), the trend is linear with \(a\) is the slope, and when \(b \sim 1\), the trend is exponential with \(a\) is the rate. So that function can cover a large family of trend.When time changes,
levelandsare updated to new values. Coefficientslevel_smands_smare used to make the transition smoothly.
When
powxis near \(0\), the error \(\sigma_t\) will be nearly constant while whenpowxis near \(1\), the error will be propotional to the expected value.There are several varieties of SGT. In this tutorial, we use generalized seasonality and seasonal average method.
We are ready to specify the model using NumPyro primitives. In NumPyro, we use the primitive sample(name, prior) to declare a latent random variable with a corresponding prior. These primitives can have custom interpretations depending on the effect handlers that are used by NumPyro inference algorithms in the backend. e.g. we can condition on specific values using the condition handler, or record values at these sample sites in the execution trace using the trace handler. Note
that these details are not important for specifying the model, or running inference, but curious readers are encouraged to read the tutorial on effect handlers in Pyro.
[4]:
def sgt(y, seasonality, future=0):
# heuristically, standard derivation of Cauchy prior depends on
# the max value of data
cauchy_sd = jnp.max(y) / 150
# NB: priors' parameters are taken from
# https://github.com/cbergmeir/Rlgt/blob/master/Rlgt/R/rlgtcontrol.R
nu = numpyro.sample("nu", dist.Uniform(2, 20))
powx = numpyro.sample("powx", dist.Uniform(0, 1))
sigma = numpyro.sample("sigma", dist.HalfCauchy(cauchy_sd))
offset_sigma = numpyro.sample(
"offset_sigma", dist.TruncatedCauchy(low=1e-10, loc=1e-10, scale=cauchy_sd)
)
coef_trend = numpyro.sample("coef_trend", dist.Cauchy(0, cauchy_sd))
pow_trend_beta = numpyro.sample("pow_trend_beta", dist.Beta(1, 1))
# pow_trend takes values from -0.5 to 1
pow_trend = 1.5 * pow_trend_beta - 0.5
pow_season = numpyro.sample("pow_season", dist.Beta(1, 1))
level_sm = numpyro.sample("level_sm", dist.Beta(1, 2))
s_sm = numpyro.sample("s_sm", dist.Uniform(0, 1))
init_s = numpyro.sample("init_s", dist.Cauchy(0, y[:seasonality] * 0.3))
def transition_fn(carry, t):
level, s, moving_sum = carry
season = s[0] * level**pow_season
exp_val = level + coef_trend * level**pow_trend + season
exp_val = jnp.clip(exp_val, 0)
# use expected vale when forecasting
y_t = jnp.where(t >= N, exp_val, y[t])
moving_sum = (
moving_sum + y[t] - jnp.where(t >= seasonality, y[t - seasonality], 0.0)
)
level_p = jnp.where(t >= seasonality, moving_sum / seasonality, y_t - season)
level = level_sm * level_p + (1 - level_sm) * level
level = jnp.clip(level, 0)
new_s = (s_sm * (y_t - level) / season + (1 - s_sm)) * s[0]
# repeat s when forecasting
new_s = jnp.where(t >= N, s[0], new_s)
s = jnp.concatenate([s[1:], new_s[None]], axis=0)
omega = sigma * exp_val**powx + offset_sigma
y_ = numpyro.sample("y", dist.StudentT(nu, exp_val, omega))
return (level, s, moving_sum), y_
N = y.shape[0]
level_init = y[0]
s_init = jnp.concatenate([init_s[1:], init_s[:1]], axis=0)
moving_sum = level_init
with numpyro.handlers.condition(data={"y": y[1:]}):
_, ys = scan(
transition_fn, (level_init, s_init, moving_sum), jnp.arange(1, N + future)
)
if future > 0:
numpyro.deterministic("y_forecast", ys[-future:])
Note that level and s are updated recursively while we collect the expected value at each time step. NumPyro uses JAX in the backend to JIT compile many critical parts of the NUTS algorithm, including the verlet integrator and the tree building process. However, doing so using Python’s for loop in the model will result in a long compilation time for the model, so we use scan - which is a wrapper of
lax.scan with supports for NumPyro primitives and handlers. A detailed explanation for using this utility can be found in NumPyro documentation. Here we use it to collect y values while the triple (level, s, moving_sum) plays the role of carrying state.
Another note is that instead of declaring the observation site y in transition_fn
numpyro.sample("y", dist.StudentT(nu, exp_val, omega), obs=y[t])
, we have used condition handler here. The reason is we also want to use this model for forecasting. In forecasting, future values of y are non-observable, so obs=y[t] does not make sense when t >= len(y) (caution: index out-of-bound errors do not get raised in JAX, e.g. jnp.arange(3)[10] == 2). Using condition, when the length of scan is larger than the length of the conditioned/observed site,
unobserved values will be sampled from the distribution of that site.
Inference
First, we want to choose a good value for seasonality. Following the demo in Rlgt, we will set seasonality=38. Indeed, this value can be guessed by looking at the plot of the training data, where the second order seasonality effect has a periodicity around \(40\) years. Note that \(38\) is also one of the highest-autocorrelation lags.
[5]:
print("Lag values sorted according to their autocorrelation values:\n")
print(jnp.argsort(autocorrelation(y_train))[::-1])
Lag values sorted according to their autocorrelation values:
[ 0 67 57 38 68 1 29 58 37 56 28 10 19 39 66 78 47 77 9 79 48 76 30 18
20 11 46 59 69 27 55 36 2 8 40 49 17 21 75 12 65 45 31 26 7 54 35 41
50 3 22 60 70 16 44 13 6 25 74 53 42 32 23 43 51 4 15 14 34 24 5 52
73 64 33 71 72 61 63 62]
Now, let us run \(4\) MCMC chains (using the No-U-Turn Sampler algorithm) with \(5000\) warmup steps and \(5000\) sampling steps per each chain. The returned value will be a collection of \(20000\) samples.
[6]:
%%time
kernel = NUTS(sgt)
mcmc = MCMC(kernel, num_warmup=5000, num_samples=5000, num_chains=4)
mcmc.run(random.key(0), y_train, seasonality=38)
mcmc.print_summary()
samples = mcmc.get_samples()
mean std median 5.0% 95.0% n_eff r_hat
coef_trend 32.33 123.99 12.07 -91.43 157.37 1307.74 1.00
init_s[0] 84.35 105.16 61.08 -59.71 232.37 4053.35 1.00
init_s[1] -21.48 72.05 -26.11 -130.13 94.34 1038.51 1.01
init_s[2] 26.08 92.13 13.57 -114.83 156.16 1559.02 1.00
init_s[3] 122.52 123.56 102.67 -59.39 305.43 4317.17 1.00
init_s[4] 443.91 254.12 395.89 69.08 789.27 3090.34 1.00
init_s[5] 1163.56 491.37 1079.23 481.92 1861.90 1562.40 1.00
init_s[6] 1968.70 649.68 1860.04 902.00 2910.49 1974.42 1.00
init_s[7] 3652.34 1107.27 3505.37 1967.67 5383.26 1669.91 1.00
init_s[8] 2593.04 831.42 2452.27 1317.67 3858.55 1805.87 1.00
init_s[9] 947.28 422.29 885.72 311.39 1589.56 3355.27 1.00
init_s[10] 44.09 102.92 28.38 -105.25 203.73 1367.99 1.00
init_s[11] -2.25 52.92 -2.71 -86.51 72.90 611.35 1.01
init_s[12] -12.22 64.98 -13.67 -110.07 85.65 892.13 1.01
init_s[13] 74.43 106.48 53.13 -79.73 225.92 658.08 1.01
init_s[14] 332.98 255.28 281.72 -11.18 697.96 3685.55 1.00
init_s[15] 965.80 389.00 893.29 373.98 1521.59 2575.80 1.00
init_s[16] 1261.12 469.99 1191.83 557.98 1937.38 2300.48 1.00
init_s[17] 1372.34 559.14 1274.21 483.96 2151.94 2007.79 1.00
init_s[18] 611.20 313.13 546.56 167.97 1087.74 2854.06 1.00
init_s[19] 17.81 87.79 8.93 -118.64 143.96 5689.95 1.00
init_s[20] -31.84 66.70 -25.15 -146.89 58.97 3083.09 1.00
init_s[21] -14.01 44.74 -5.80 -86.03 42.99 2118.09 1.00
init_s[22] -2.26 42.99 -2.39 -61.40 66.34 3022.51 1.00
init_s[23] 43.53 90.60 29.14 -82.56 167.89 3230.17 1.00
init_s[24] 509.69 326.73 453.22 44.04 975.15 2087.02 1.00
init_s[25] 919.23 431.15 837.03 284.54 1563.05 3257.27 1.00
init_s[26] 1783.39 697.15 1660.09 720.83 2811.83 1730.70 1.00
init_s[27] 1247.60 461.26 1172.88 544.44 1922.68 1573.09 1.00
init_s[28] 217.92 169.08 191.38 -29.78 456.65 4899.06 1.00
init_s[29] -7.43 82.23 -12.99 -133.20 118.31 7588.25 1.00
init_s[30] -6.69 86.99 -17.03 -130.99 125.43 1687.37 1.00
init_s[31] -35.24 71.31 -35.75 -148.09 76.96 5462.22 1.00
init_s[32] -8.63 80.39 -14.95 -138.34 113.89 6626.25 1.00
init_s[33] 117.38 148.71 91.69 -78.12 316.69 2424.57 1.00
init_s[34] 502.79 297.08 448.55 87.88 909.45 1863.99 1.00
init_s[35] 1064.57 445.88 984.10 391.61 1710.35 2584.45 1.00
init_s[36] 1849.48 632.44 1763.31 861.63 2800.25 1866.47 1.00
init_s[37] 1452.62 546.57 1382.62 635.28 2257.04 2343.09 1.00
level_sm 0.00 0.00 0.00 0.00 0.00 7829.05 1.00
nu 12.17 4.73 12.31 5.49 19.99 4979.84 1.00
offset_sigma 31.82 31.84 22.43 0.01 73.13 1442.32 1.00
pow_season 0.09 0.04 0.09 0.01 0.15 1091.99 1.00
pow_trend_beta 0.26 0.18 0.24 0.00 0.52 199.20 1.01
powx 0.62 0.13 0.62 0.40 0.84 2476.16 1.00
s_sm 0.08 0.09 0.05 0.00 0.18 5866.57 1.00
sigma 9.67 9.87 6.61 0.35 20.60 2376.07 1.00
Number of divergences: 4568
CPU times: user 1min 17s, sys: 108 ms, total: 1min 18s
Wall time: 41.2 s
Forecasting
Given samples from mcmc, we want to do forecasting for the testing dataset y_test. NumPyro provides a convenient utility Predictive to get predictive distribution. Let’s see how to use it to get forecasting values.
Notice that in the sgt model defined above, there is a keyword future which controls the execution of the model - depending on whether future > 0 or future == 0. The following code predicts the last 34 values from the original time-series.
[7]:
predictive = Predictive(sgt, samples, return_sites=["y_forecast"])
forecast_marginal = predictive(random.key(1), y_train, seasonality=38, future=34)[
"y_forecast"
]
Let’s get sMAPE, root mean square error of the prediction, and visualize the result with the mean prediction and the 90% highest posterior density interval (HPDI).
[8]:
y_pred = jnp.mean(forecast_marginal, axis=0)
sMAPE = jnp.mean(jnp.abs(y_pred - y_test) / (y_pred + y_test)) * 200
msqrt = jnp.sqrt(jnp.mean((y_pred - y_test) ** 2))
print("sMAPE: {:.2f}, rmse: {:.2f}".format(sMAPE, msqrt))
sMAPE: 63.93, rmse: 1249.29
Finally, let’s plot the result to verify that we get the expected one.
[9]:
plt.figure(figsize=(8, 4))
plt.plot(lynx["time"], data)
t_future = lynx["time"][80:]
hpd_low, hpd_high = hpdi(forecast_marginal)
plt.plot(t_future, y_pred, lw=2)
plt.fill_between(t_future, hpd_low, hpd_high, alpha=0.3)
plt.title("Forecasting lynx dataset with SGT model (90% HPDI)")
plt.show()
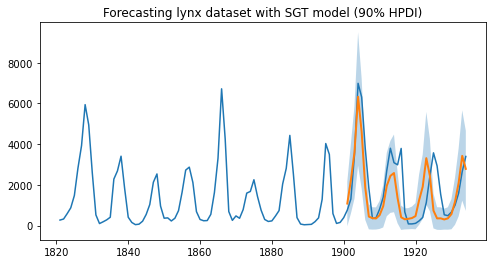
As we can observe, the model has been able to learn both the first and second order seasonality effects, i.e. a cyclical pattern with a periodicity of around 10, as well as spikes that can be seen once every 40 or so years. Moreover, we not only have point estimates for the forecast but can also use the uncertainty estimates from the model to bound our forecasts.
Acknowledgements
We would like to thank Slawek Smyl for many helpful resources and suggestions. Fast inference would not have been possible without the support of JAX and the XLA teams, so we would like to thank them for providing such a great open-source platform for us to build on, and for their responsiveness in dealing with our feature requests and bug reports.
References
[1] Rlgt: Bayesian Exponential Smoothing Models with Trend Modifications, Slawek Smyl, Christoph Bergmeir, Erwin Wibowo, To Wang Ng, Trustees of Columbia University