Note
Click here to download the full example code
Example: Hidden Markov Model¶
In this example, we will follow [1] to construct a semi-supervised Hidden Markov Model for a generative model with observations are words and latent variables are categories. Instead of automatically marginalizing all discrete latent variables (as in [2]), we will use the “forward algorithm” (which exploits the conditional independent of a Markov model - see [3]) to iteratively do this marginalization.
The semi-supervised problem is chosen instead of an unsupervised one because it is hard to make the inference works for an unsupervised model (see the discussion [4]). On the other hand, this example also illustrates the usage of JAX’s lax.scan primitive. The primitive will greatly improve compiling for the model.
References:
import argparse
import os
import time
import matplotlib.pyplot as plt
import numpy as np
from scipy.stats import gaussian_kde
from jax import lax, random
import jax.numpy as jnp
from jax.scipy.special import logsumexp
import numpyro
import numpyro.distributions as dist
from numpyro.infer import MCMC, NUTS
def simulate_data(
rng_key, num_categories, num_words, num_supervised_data, num_unsupervised_data
):
rng_key, rng_key_transition, rng_key_emission = random.split(rng_key, 3)
transition_prior = jnp.ones(num_categories)
emission_prior = jnp.repeat(0.1, num_words)
transition_prob = dist.Dirichlet(transition_prior).sample(
key=rng_key_transition, sample_shape=(num_categories,)
)
emission_prob = dist.Dirichlet(emission_prior).sample(
key=rng_key_emission, sample_shape=(num_categories,)
)
start_prob = jnp.repeat(1.0 / num_categories, num_categories)
categories, words = [], []
for t in range(num_supervised_data + num_unsupervised_data):
rng_key, rng_key_transition, rng_key_emission = random.split(rng_key, 3)
if t == 0 or t == num_supervised_data:
category = dist.Categorical(start_prob).sample(key=rng_key_transition)
else:
category = dist.Categorical(transition_prob[category]).sample(
key=rng_key_transition
)
word = dist.Categorical(emission_prob[category]).sample(key=rng_key_emission)
categories.append(category)
words.append(word)
# split into supervised data and unsupervised data
categories, words = jnp.stack(categories), jnp.stack(words)
supervised_categories = categories[:num_supervised_data]
supervised_words = words[:num_supervised_data]
unsupervised_words = words[num_supervised_data:]
return (
transition_prior,
emission_prior,
transition_prob,
emission_prob,
supervised_categories,
supervised_words,
unsupervised_words,
)
def forward_one_step(prev_log_prob, curr_word, transition_log_prob, emission_log_prob):
log_prob_tmp = jnp.expand_dims(prev_log_prob, axis=1) + transition_log_prob
log_prob = log_prob_tmp + emission_log_prob[:, curr_word]
return logsumexp(log_prob, axis=0)
def forward_log_prob(
init_log_prob, words, transition_log_prob, emission_log_prob, unroll_loop=False
):
# Note: The following naive implementation will make it very slow to compile
# and do inference. So we use lax.scan instead.
#
# >>> log_prob = init_log_prob
# >>> for word in words:
# ... log_prob = forward_one_step(log_prob, word, transition_log_prob, emission_log_prob)
def scan_fn(log_prob, word):
return (
forward_one_step(log_prob, word, transition_log_prob, emission_log_prob),
None, # we don't need to collect during scan
)
if unroll_loop:
log_prob = init_log_prob
for word in words:
log_prob = forward_one_step(
log_prob, word, transition_log_prob, emission_log_prob
)
else:
log_prob, _ = lax.scan(scan_fn, init_log_prob, words)
return log_prob
def semi_supervised_hmm(
transition_prior,
emission_prior,
supervised_categories,
supervised_words,
unsupervised_words,
unroll_loop=False,
):
num_categories, num_words = transition_prior.shape[0], emission_prior.shape[0]
transition_prob = numpyro.sample(
"transition_prob",
dist.Dirichlet(
jnp.broadcast_to(transition_prior, (num_categories, num_categories))
),
)
emission_prob = numpyro.sample(
"emission_prob",
dist.Dirichlet(jnp.broadcast_to(emission_prior, (num_categories, num_words))),
)
# models supervised data;
# here we don't make any assumption about the first supervised category, in other words,
# we place a flat/uniform prior on it.
numpyro.sample(
"supervised_categories",
dist.Categorical(transition_prob[supervised_categories[:-1]]),
obs=supervised_categories[1:],
)
numpyro.sample(
"supervised_words",
dist.Categorical(emission_prob[supervised_categories]),
obs=supervised_words,
)
# computes log prob of unsupervised data
transition_log_prob = jnp.log(transition_prob)
emission_log_prob = jnp.log(emission_prob)
init_log_prob = emission_log_prob[:, unsupervised_words[0]]
log_prob = forward_log_prob(
init_log_prob,
unsupervised_words[1:],
transition_log_prob,
emission_log_prob,
unroll_loop,
)
log_prob = logsumexp(log_prob, axis=0, keepdims=True)
# inject log_prob to potential function
numpyro.factor("forward_log_prob", log_prob)
def print_results(posterior, transition_prob, emission_prob):
header = semi_supervised_hmm.__name__ + " - TRAIN"
columns = ["", "ActualProb", "Pred(p25)", "Pred(p50)", "Pred(p75)"]
header_format = "{:>20} {:>10} {:>10} {:>10} {:>10}"
row_format = "{:>20} {:>10.2f} {:>10.2f} {:>10.2f} {:>10.2f}"
print("\n", "=" * 20 + header + "=" * 20, "\n")
print(header_format.format(*columns))
quantiles = np.quantile(posterior["transition_prob"], [0.25, 0.5, 0.75], axis=0)
for i in range(transition_prob.shape[0]):
for j in range(transition_prob.shape[1]):
idx = "transition[{},{}]".format(i, j)
print(
row_format.format(idx, transition_prob[i, j], *quantiles[:, i, j]), "\n"
)
quantiles = np.quantile(posterior["emission_prob"], [0.25, 0.5, 0.75], axis=0)
for i in range(emission_prob.shape[0]):
for j in range(emission_prob.shape[1]):
idx = "emission[{},{}]".format(i, j)
print(
row_format.format(idx, emission_prob[i, j], *quantiles[:, i, j]), "\n"
)
def main(args):
print("Simulating data...")
(
transition_prior,
emission_prior,
transition_prob,
emission_prob,
supervised_categories,
supervised_words,
unsupervised_words,
) = simulate_data(
random.PRNGKey(1),
num_categories=args.num_categories,
num_words=args.num_words,
num_supervised_data=args.num_supervised,
num_unsupervised_data=args.num_unsupervised,
)
print("Starting inference...")
rng_key = random.PRNGKey(2)
start = time.time()
kernel = NUTS(semi_supervised_hmm)
mcmc = MCMC(
kernel,
num_warmup=args.num_warmup,
num_samples=args.num_samples,
num_chains=args.num_chains,
progress_bar=False if "NUMPYRO_SPHINXBUILD" in os.environ else True,
)
mcmc.run(
rng_key,
transition_prior,
emission_prior,
supervised_categories,
supervised_words,
unsupervised_words,
args.unroll_loop,
)
samples = mcmc.get_samples()
print_results(samples, transition_prob, emission_prob)
print("\nMCMC elapsed time:", time.time() - start)
# make plots
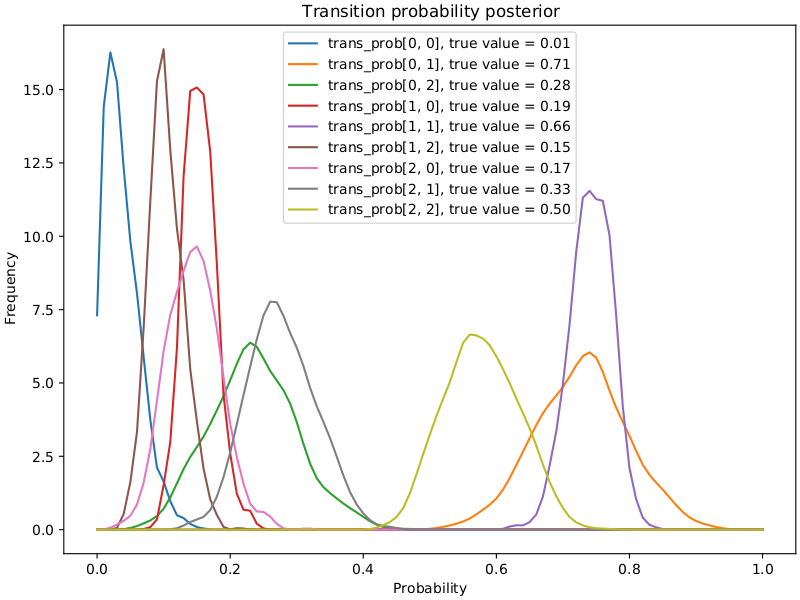
fig, ax = plt.subplots(figsize=(8, 6), constrained_layout=True)
x = np.linspace(0, 1, 101)
for i in range(transition_prob.shape[0]):
for j in range(transition_prob.shape[1]):
ax.plot(
x,
gaussian_kde(samples["transition_prob"][:, i, j])(x),
label="trans_prob[{}, {}], true value = {:.2f}".format(
i, j, transition_prob[i, j]
),
)
ax.set(
xlabel="Probability",
ylabel="Frequency",
title="Transition probability posterior",
)
ax.legend()
plt.savefig("hmm_plot.pdf")
if __name__ == "__main__":
assert numpyro.__version__.startswith("0.7.0")
parser = argparse.ArgumentParser(description="Semi-supervised Hidden Markov Model")
parser.add_argument("--num-categories", default=3, type=int)
parser.add_argument("--num-words", default=10, type=int)
parser.add_argument("--num-supervised", default=100, type=int)
parser.add_argument("--num-unsupervised", default=500, type=int)
parser.add_argument("-n", "--num-samples", nargs="?", default=1000, type=int)
parser.add_argument("--num-warmup", nargs="?", default=500, type=int)
parser.add_argument("--num-chains", nargs="?", default=1, type=int)
parser.add_argument("--unroll-loop", action="store_true")
parser.add_argument("--device", default="cpu", type=str, help='use "cpu" or "gpu".')
args = parser.parse_args()
numpyro.set_platform(args.device)
numpyro.set_host_device_count(args.num_chains)
main(args)